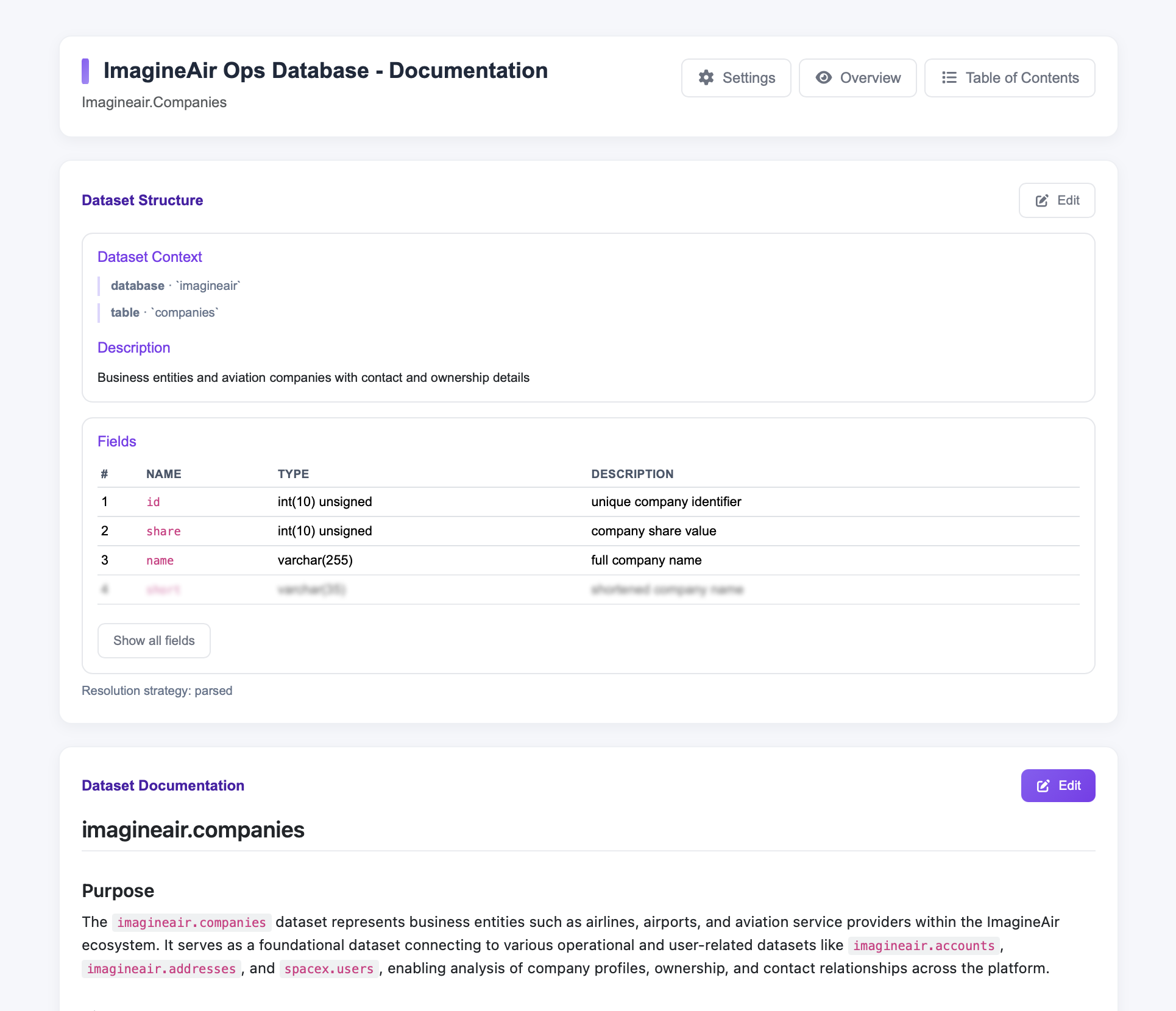
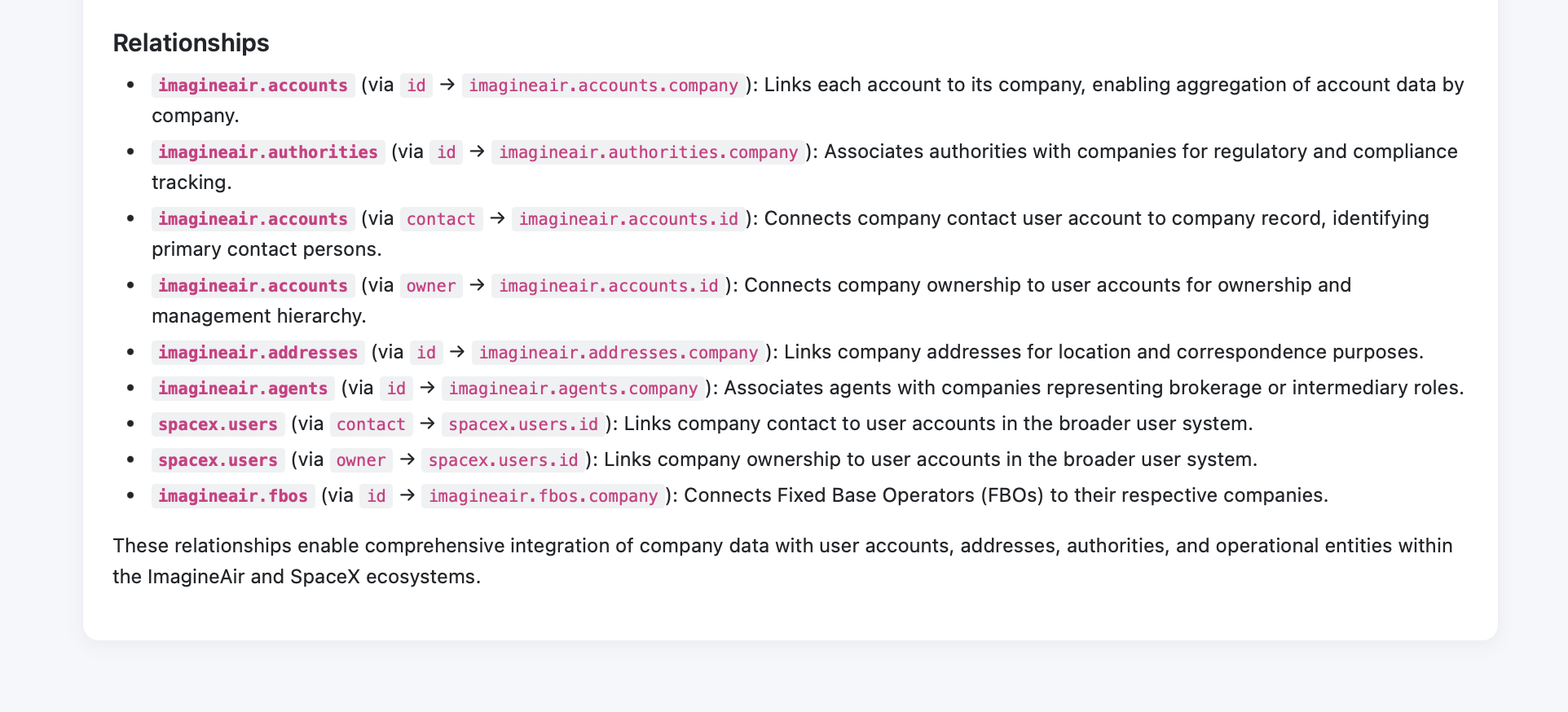
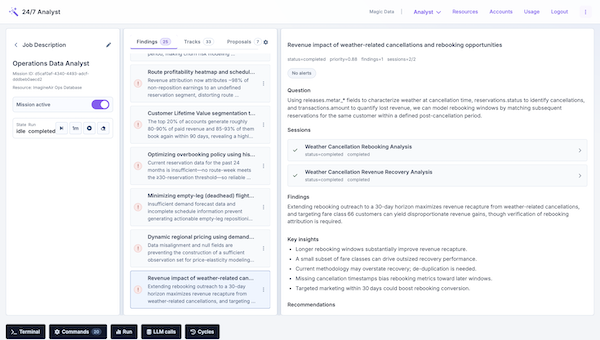
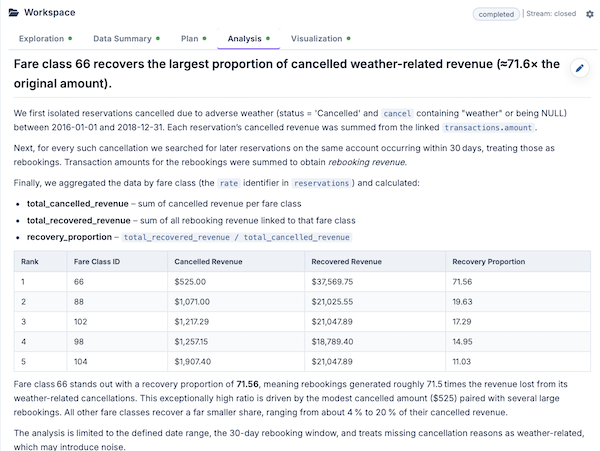
Use case · 01
Analytics / Anomaly Detection
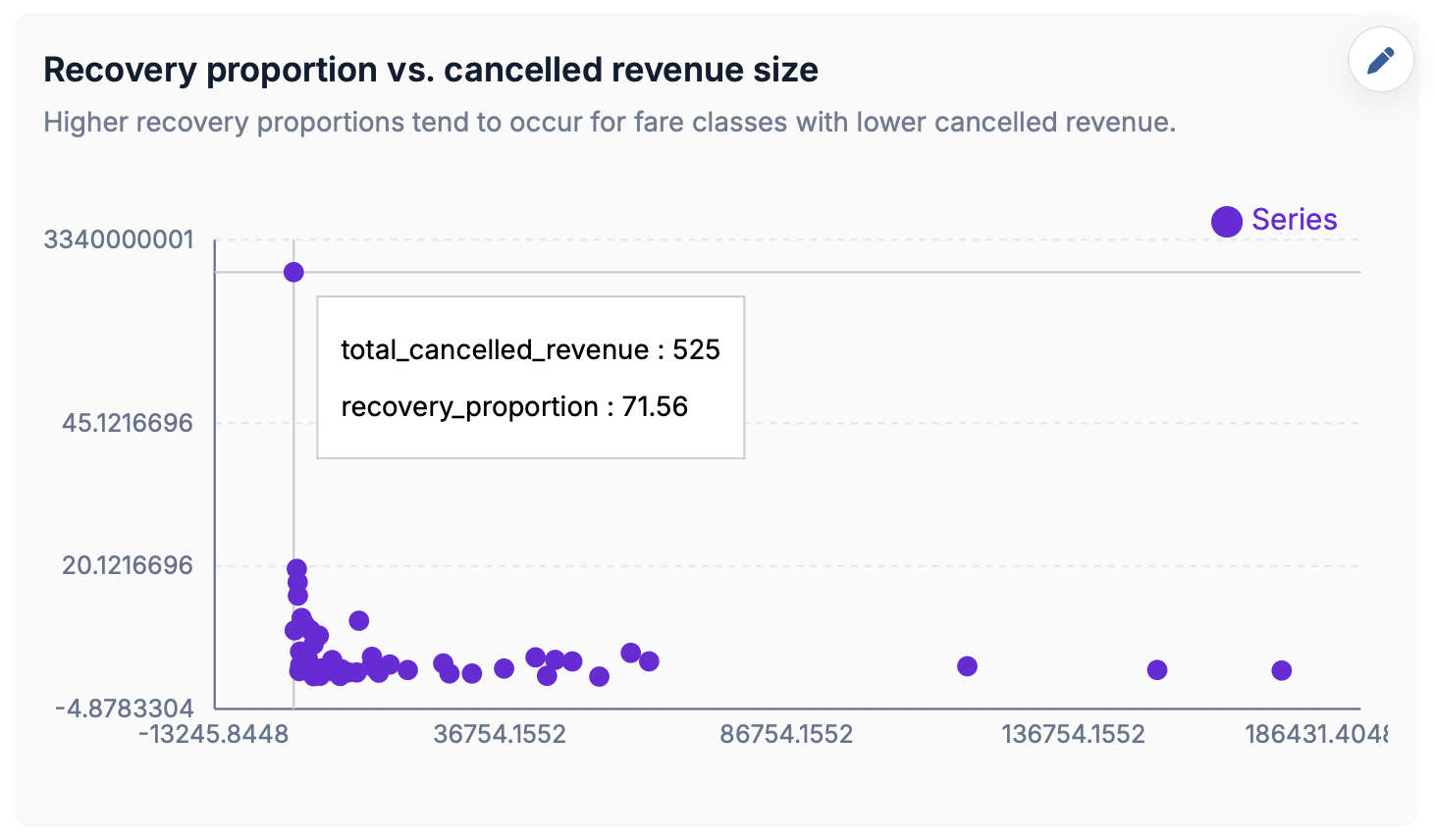
Magic Data prepared an anomaly detection workflow for a supply chain inventory platform that surfaced unusual patterns across spend, volatility, supplier concentration, delivery performance, and onboarding trends. Those outputs gave the customer success team account-specific renewal and upsell narratives they could take directly into commercial conversations, turning raw operational data into actionable revenue moments.